训练分类器
本指南介绍如何在 OV20i 摄像系统上配置并训练分类模型。当您需要基于视觉特征自动将对象分类到不同类别时,请使用本流程。
视频指南
请观看本主题的演示:OV Auto-Defect Creator Studio
何时使用分类: 根据类型、尺寸、颜色或状态对零件进行分类;识别不同的产品变体;具有多种可接受类别的质量控制。
先决条件
- 已配置成像设置的活动配方
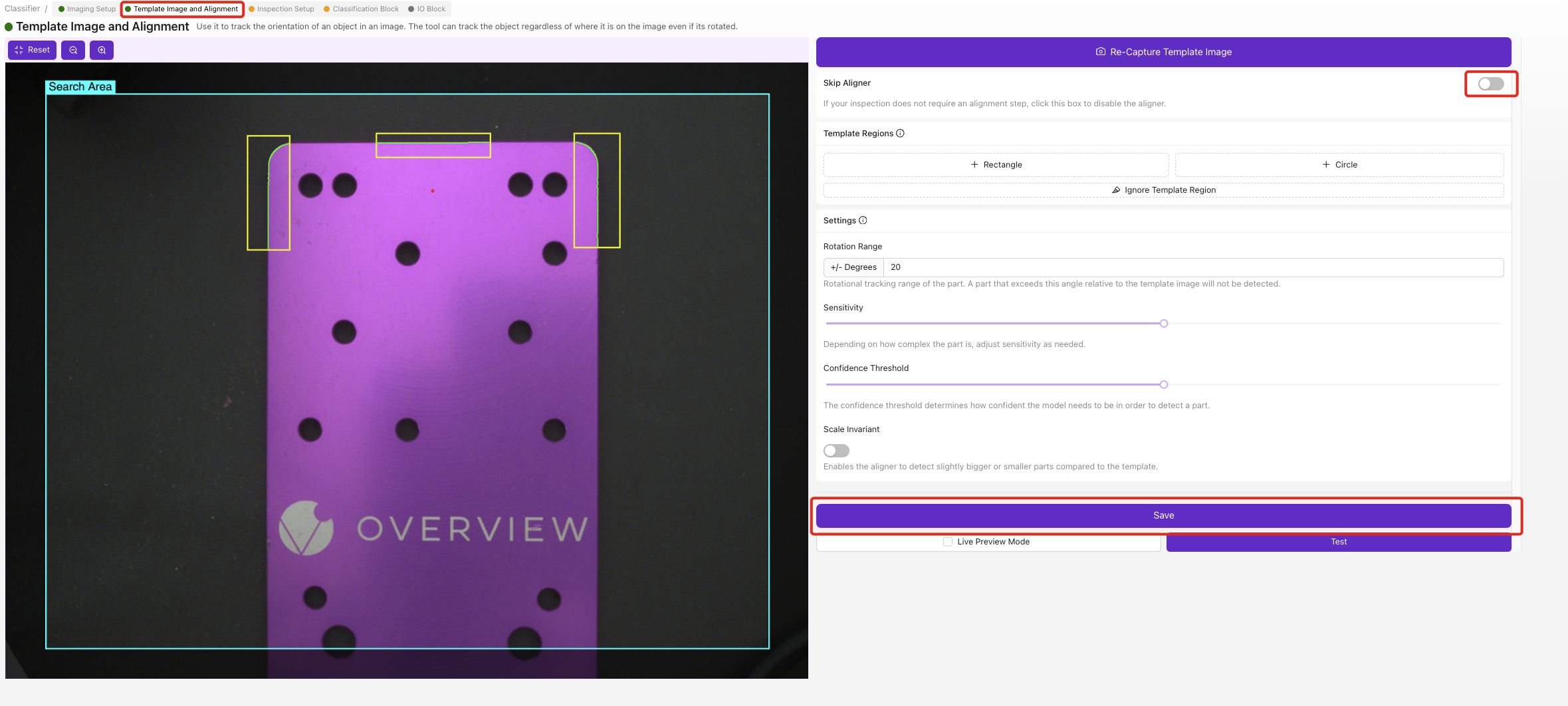
- 模板图像和对齐已完成(或跳过)
- 已定义检测 ROI
- 代表要检测的每个类别的样本对象
第 1 步:访问 Classification Block
1.1 导航至 Classification Block(分类区块)
- 点击面包屑导航中的 Classification Block(分类区块),或
- 在导航栏的下拉菜单中选择
![]()
1.2 验证前提条件
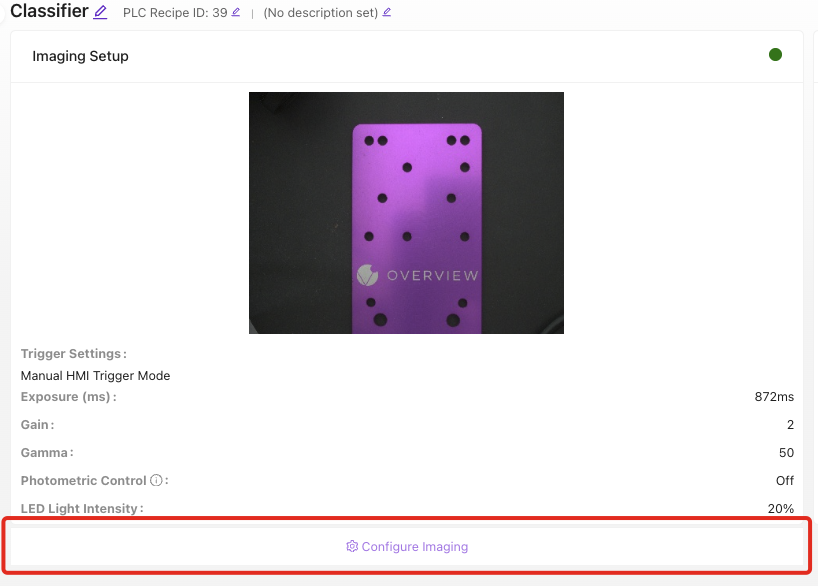
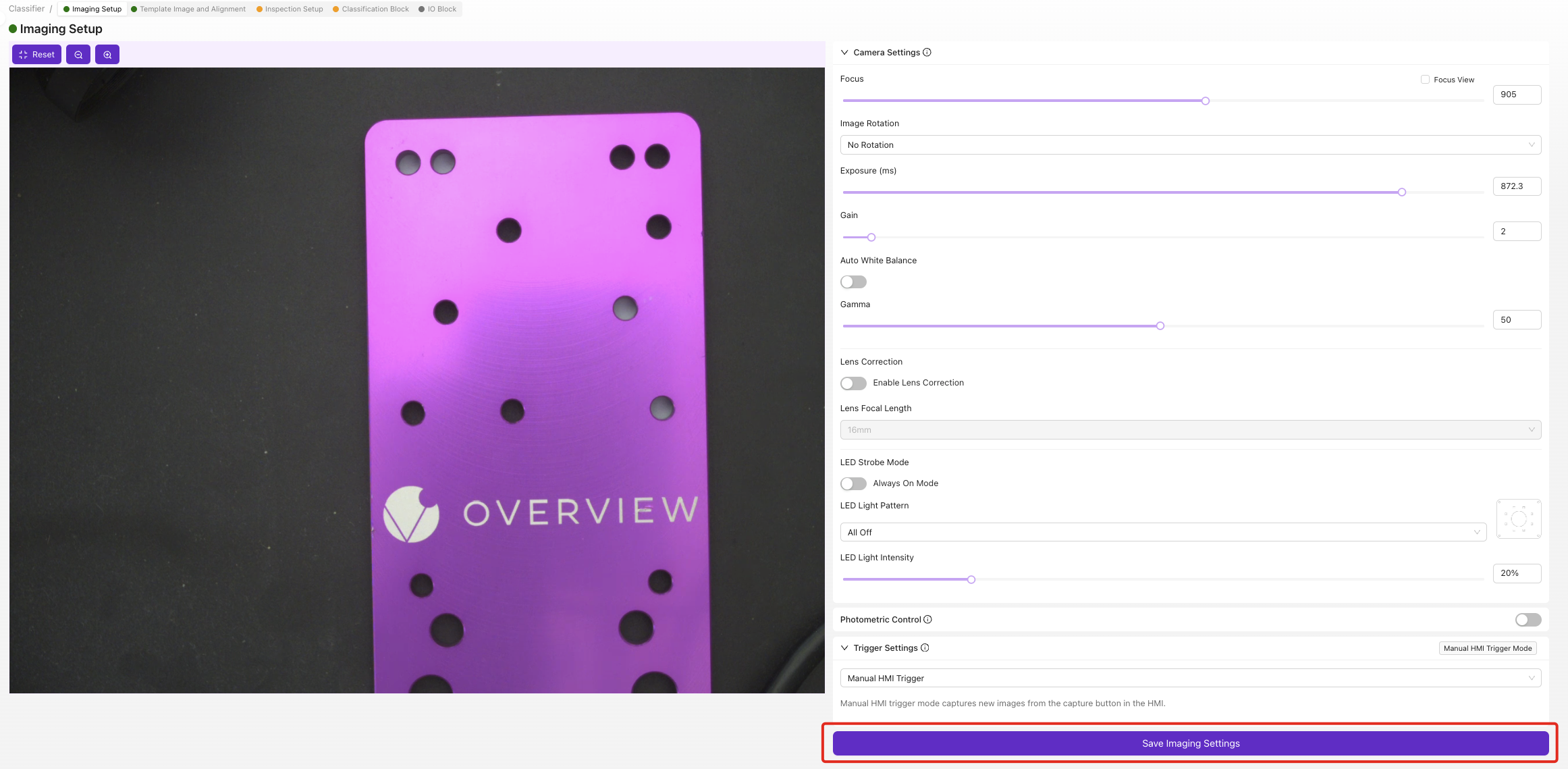
确保以下区块显示为绿色状态:
- ✅ 成像设置
- ✅ 模板与对齐(或跳过)
- ✅ 检测设置
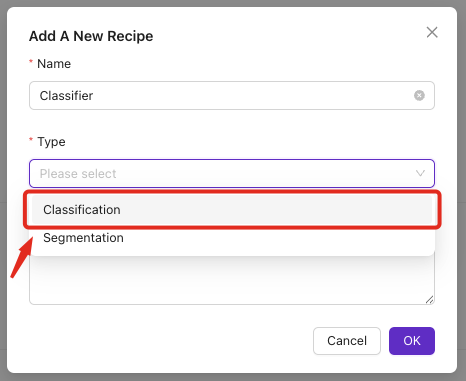
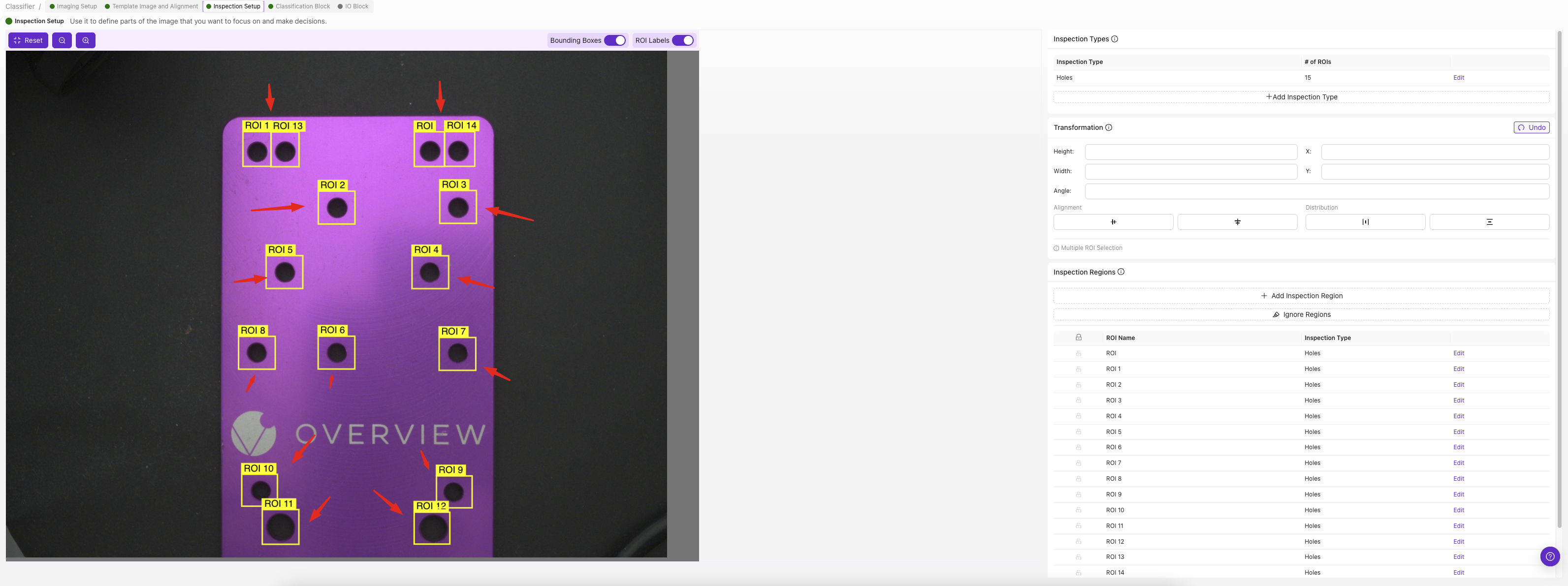
第 2 步:创建 Classification 类
2.1 定义您的类别
- 在“Inspection Types”下点击
Edit - 为要检测的每个类别添加类别
2.2 配置每个类别
对于每个类别:
- 输入类别名称: 使用描述性名称(例如 “Small”、“Medium”、“Large”)
- 选择类别颜色: 选取用于视觉识别的不同颜色
- 添加描述: 关于该类别的可选详细信息
- 点击
Save
2.3 分类命名最佳实践
| 良好名称 | 不佳名称 |
|---|---|
| Small_Bolt, Medium_Bolt, Large_Bolt | Type1, Type2, Type3 |
| Red_Cap, Blue_Cap, Green_Cap | Color1, Color2, Color3 |
| Good_Part, Defective_Part | Pass, Fail |
| Screw_PhillipsHead, Screw_Flathead | A, B |
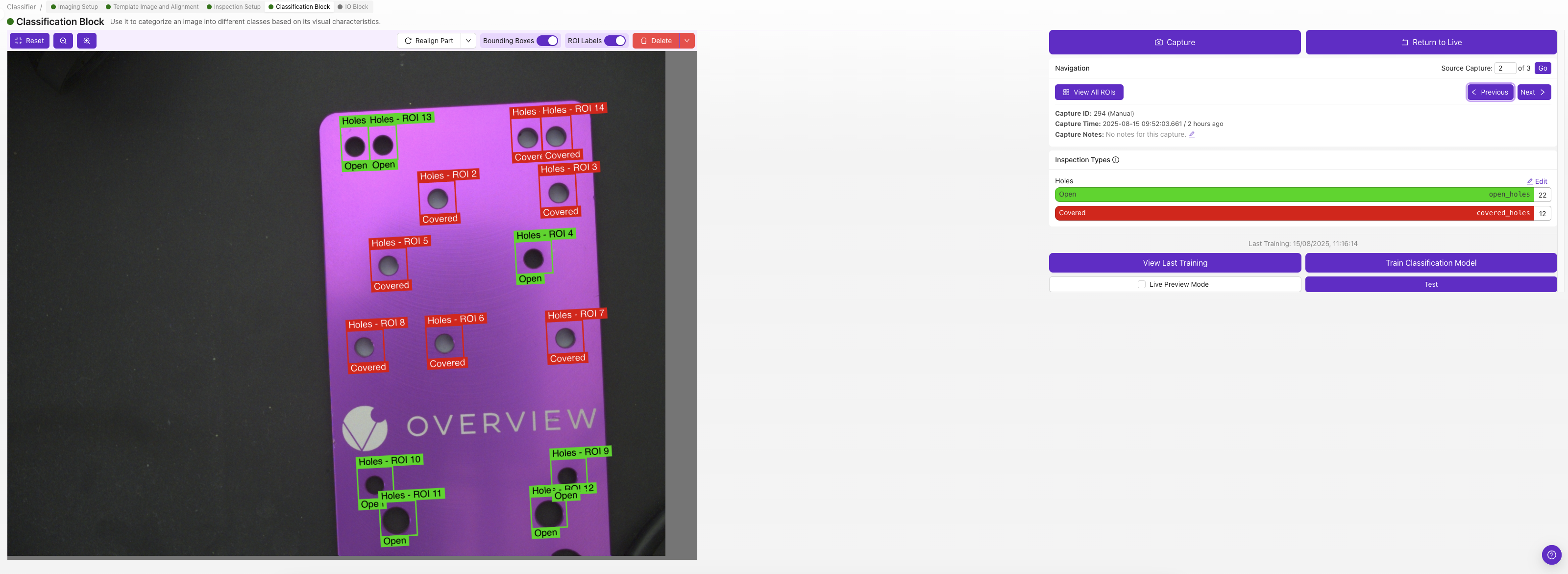
第 3 步:捕获训练图像
3.1 图像捕获流程
对于每个类别,至少捕获 5 张图像(推荐 10 张以上):
- 放置对象 代表该类别在检查区域内
- 核实对象在 ROI 边界内
- 点击
Capture以拍摄训练图像 - 从下拉列表中选择适当的类别
- 点击
Save以存储带标签的图像 - 对同一类别的不同示例重复上述步骤
3.2 训练数据要求
| 类别 | 最小图像数 | 推荐图像数 | 备注 |
|---|---|---|---|
| 每个类别 | 5 | 10-15 | 图像越多,准确性越高 |
| 总数据集 | 15 张以上 | 30-50 张以上 | 在所有类别之间保持平衡 |
| 边缘情况 | 每个类别 2-3 张 | 每个类别 5 张以上 | 边界示例 |
3.3 训练图像最佳实践
应:
- 在每个类别内使用不同的示例
- 改变对象的方向和位置
- 包含良好的照明条件
- 捕获边缘情况和边界示例
- 保持一致的 ROI 取景
不应:
- 重复使用相同对象
- 在一个 ROI 中包含多个对象
- 在单图像中混合不同类别
- 使用模糊或光线不足的图像
- 拍摄之间更改 ROI 大小
3.4 质量控制
After capturing each image:
- 在预览中检查图像质量
- 验证是否分配了正确的类别标签
- 使用
Delete按钮删除质量较差的图像 - 如有需要,重新拍摄
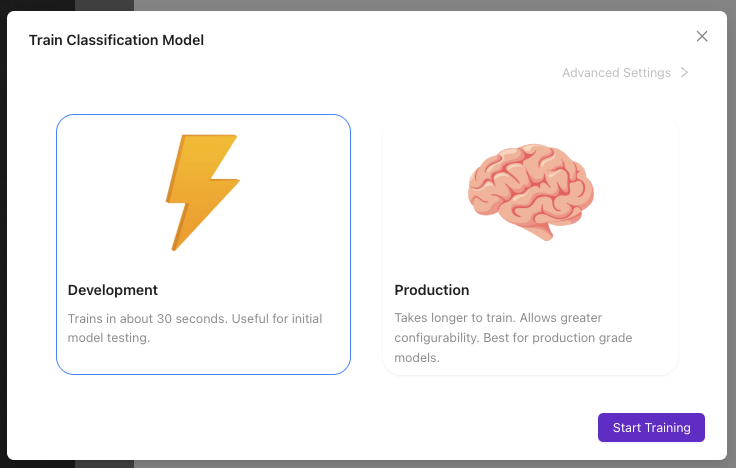
第 4 步:配置训练参数
4.1 进入训练设置
- 点击
Train Classification Model按钮
4.2 选择训练模式
根据需要进行选择:
| 训练模式 | 时长 | 精度 | 应用场景 |
|---|---|---|---|
| 快速 | 2-5 分钟 | 适合测试 | 初始模型验证 |
| 平衡 | 5-15 分钟 | 可用于生产 | 大多数应用场景 |
| 高精度 | 15-30 分钟 | 最高精度 | 关键应用 |
4.3 设置迭代次数
手动迭代设置:
- 低 (50-100): 快速测试,基本精度
- 中 (200-500): 生产就绪质量
- 高 (500+): 最高精度,训练速度较慢
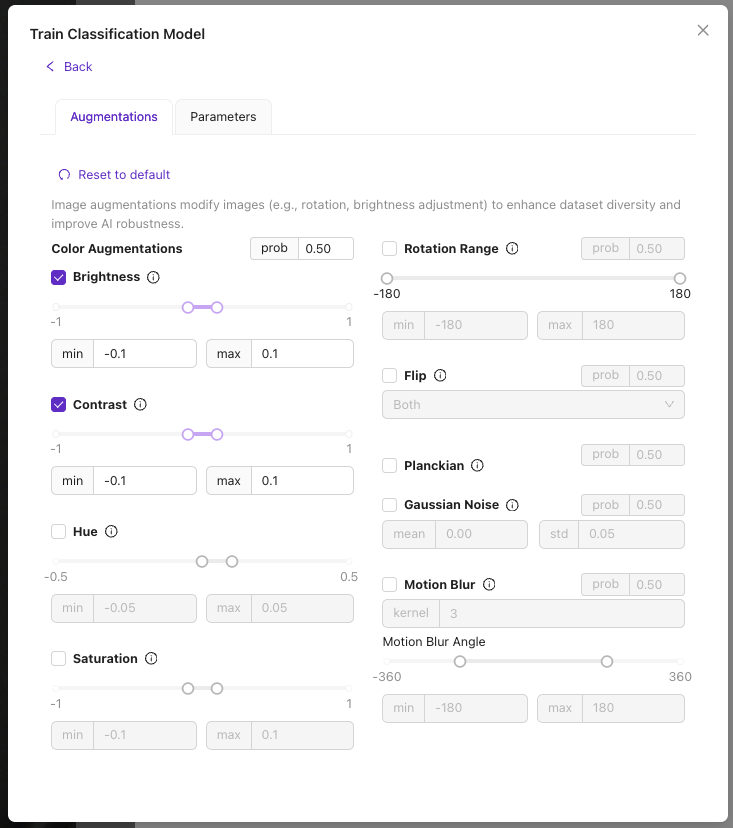
4.4 高级设置(可选)
Batch Size:
- 较小批量: 训练更稳定,速度较慢
- 较大批量: 训练更快,可能不太稳定
Learning Rate:
- 较低数值: 更稳定,学习更慢
- 较高数值: 学习更快,易产生不稳定
建议: 除非有特定性能需求,否则使用默认设置。
第 5 步:开始训练过程
5.1 初始化训练
- 检查训练配置
- 点击
Start Training - 在训练模态框中监控进度
5.2 训练进度指标
监控以下指标:
- 当前迭代: 训练循环的进度
- 训练精度: 模型在训练数据上的表现
- 预计时间: 剩余训练时长
- 损失值: 模型误差(应随时间下降)
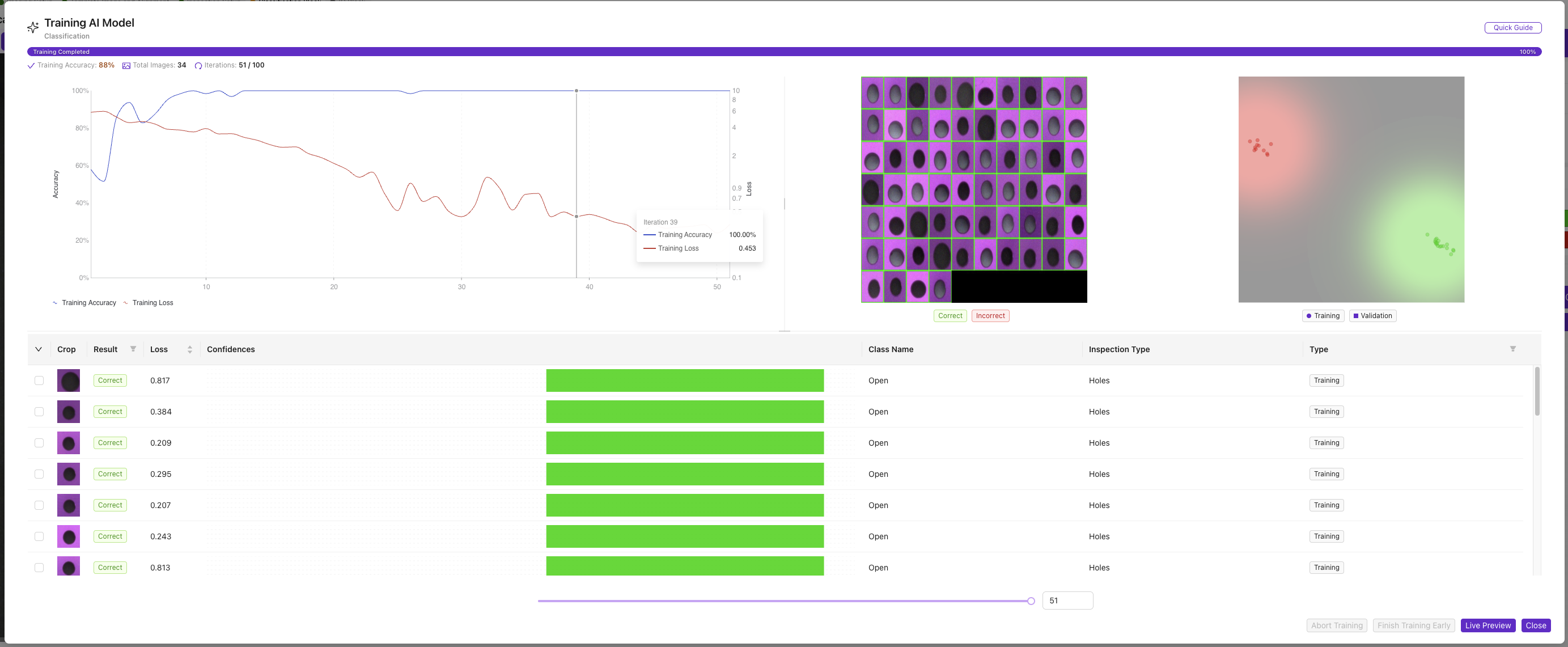
5.3 训练控制
训练过程中可用的操作:
- 中止训练: 立即停止训练
- 提前完成: 在当前精度足够时停止
- 扩展训练: 如有需要,添加更多迭代
5.4 训练完成
训练在以下情况自动停止:
- 达到目标精度(通常 ≥95%)
- 达到最大迭代次数
- 用户手动停止训练
第 6 步:评估模型性能
6.1 评审训练结果
检查最终指标:
- 最终精度: 生产使用应大于 85%
- 训练时间: 记录持续时间以备将来参考
- 收敛性: 验证精度是否稳定
6.2 模型质量指标
| 精度范围 | 质量等级 | 建议 |
|---|---|---|
| 95%+ | 优秀 | 可用于生产 |
| 85-94% | 良好 | 适用于大多数应用 |
| 75-84% | 一般 | 考虑增加训练数据 |
| <75% | 较差 | 使用更多/更高质量的图像重新训练 |
6.3 诊断模型性能不佳
| 问题 | 可能原因 | 解决方法 |
|---|---|---|
| 低精度 (<75%) | 训练数据不足 | 增加带标签的图像数量 |
| 训练没有改善 | 图像质量差 | 改善照明/对焦 |
| 类别混淆 | 外观相似的对象 | 增加更多具有辨识性的示例 |
| 过拟合 | 每个类别的图像过少 | 在类别间平衡数据集 |
第 7 步:分类性能测试
7.1 实时测试
- 点击
Live Preview以访问实时测试 - 将测试对象放置在检测区域
- 观察分类结果:
- 预测的类别名称
- 置信度百分比
- 处理时间
7.2 验证测试
系统化验证过程:
| 测试对象 | 预期类别 | 实际结果 | 置信度 | 通过/失败 |
|---|---|---|---|---|
| 已知类别 A 对象 | A 类 | _____ | ____% | ☐ |
| 已知类别 B 对象 | B 类 | _____ | ____% | ☐ |
| 边界样本 | A 类或 B 类 | _____ | ____% | ☐ |
| 未知对象 | 低置信度 | _____ | ____% | ☐ |
7.3 性能验证
验证以下方面:
- 准确性: 针对已知对象的正确分类
- 置信度: 对清晰样本具高置信度 (>80%)
- 一致性: 对同一对象的结果可重复
- 速度: 满足您应用的可接受处理时间
第 8 步:模型优化
8.1 性能不佳时
迭代改进过程:
- 识别问题区域:
- 哪些类别容易混淆?
- 哪些对象被错误分类?
- 置信度水平是否合适?
- 添加定向训练数据:
- 更多混淆类别的样本
- 边界案例和边界样本
- 不同光照/定位条件
- 重新训练模型:
- 使用 "Accurate" 模式以获得更好性能
- 提高迭代次数
- 监控准确性的提升
8.2 高级优化
适用于关键应用:
- 数据增强: 采用不同光照和位置
- 迁移学习: 从相似训练模型开始
- 集成方法: 组合多个模型
- 定期重新训练: 使用新的生产数据进行更新
第 9 步:完成配置
9.1 保存模型
- 验证满意的性能
- 模型在训练完成时会自动保存
- 记录模型版本以供文档使用
9.2 文档
记录以下细节:
- 训练日期和版本
- 每个类别的图像数量
- 使用的训练模式和迭代次数
- 达成的最终准确度
- 任何特殊注意事项
9.3 备份配置
- 导出配方 以备份
- 如有需要,单独保存训练图像
- 记录模型参数
成功!您的分类器已就绪
您的训练分类模型现在可以:
- 自动将对象分类到定义的类别
- 为每个预测提供置信度分数
- 实时处理图像以用于生产使用
- 与 I/O 逻辑 集成以实现自动化决策
进行中的维护
定期模型更新
- 随时间监控性能
- 按需添加新的训练数据
- 定期重新训练以维持准确性
- 为新产品变体更新类别
性能监控
- 跟踪生产中的准确性指标
- 识别模型性能的漂移
- 根据性能下降情况安排重新训练
下一步
在训练完分类器后:
- 配置 I/O 逻辑 以进行通过/不通过 决策
- 在 IO Block 中设置生产工作流
- 对完整检测系统进行端到端测试
- 部署到生产环境
常见陷阱
| Pitfall | Impact | Prevention |
|---|---|---|
| 训练数据不足 | 准确性较差 | 每个类别至少 10 张图像 |
| 类别失衡 | 预测偏差 | 各类别图像数量相等 |
| 图像质量差 | 结果不一致 | 优化照明和对焦 |
| 类别过于相似 | 分类混淆 | 选择明确的类别定义 |
| 无验证测试 | 生产失败 | 始终对未见对象进行测试 |